Nonphotorealistic techniques have become an increasingly popular topic in research circles. These methods provide a stylistic approach to draw images. We wish to achieve styles that are reminiscent of paintings or other forms of artistic illustration. One of more interesting modes of expression is the watercolour process. In this method the artist combines layers of translucent paints to yield the desired colours and opacities. The soft mixture of hues and the hints of curvature and shape can convey a rich, organic and natural feel to a scene.
All watercolour paints are microscopic particles (commonly known as pigments) suspended in a water-based solution. Watercolour paper is made from very small linen or cotton fibres compressed very tightly together to form a flat sheet. The binder and surfactants in watercolour paints allow the pigments to soak into the watercolour paper. We can control the rate and extent at which the water is absorbed and diffused by applying a very thin solution of cellulose on the paper.
There are several approaches to model the watercolour process. One method is based on a shallow-water fluid simulation by Kubelka and Munk [88]. The result is very convincing as it faithfully reproduces the subtle interactions between paint and paper. An alternate method is briefly discussed herein. Although the model is not as precise, we can still achieve very good results at interactive rates. Since, by its very nature, watercolour rendering is nonphotorealistic we can take several artistic liberties.
Lum and Ma developed a rendering technique that depicts a scene by compositing several layers of translucent watercolour paint [94]. Each layer of paint begins as the visualisation of Perlin Noise [96, 97] in a uniformly sampled volume. The noise varies smoothly from one sample point to the next, much like how subtle shifts in tone can be achieved with watercolours. To soften the transitions of tone one may also apply bias and gain to the noise. Bias controls the tone of a sample point and gain controls the shifts in tone from one sample point to another. To convey the general shape of a surface, each layer of paint undergoes line integral convolution (LIC) along a principle curvature of the surface in three-dimensional space [87, 92, 98]. Applying LIC to the layer smears the noise in the direction of the surface gradient. Bias and gain can be applied to again to smooth the layer even further, yielding something that a wet brush could produce. See section 9.1 Source Code for a simple implementation of Perlin Noise and LIC.
Watercolour paper is white. As the artist creates a scene, she applies a very thin layer of paint to depict areas of lightness. She then applies very thick or multiple layers of paint to convey portions of the scene that are dark. This technique is known as colour subtraction and is the opposite to the colour model of computer graphics. As such, the lighting model for watercolour rendering is the inversion of the tradtional lighting equations.
The first step in watercolour rendering is to identify specular regions of a surface. No paint or just a very thin layer is added to these regions. Next, we apply a diffuse layer where appropriate. The thickness of the diffuse layer is given by the equation.
![]()
where v is view vector and r is the direction of reflected light. To fade the amount of paint in areas of decreasing diffuse illumination an alternate equation is used [93].
![]()
where l is the light source direction and n is the surface normal. The third step is to paint those regions that receive little amounts of diffuse lighting. The thickness of the 'dark' layer is given by the equation.
![]()
Lastly, we apply subtle hints of wet brush strokes to help convey surface roundness. This layer is formed with Perlin Noise where gain and bias is applied before LIC.
The thickness of each layer is also determined by the degree at which a surface patch faces the viewpoint. The thickest of layers are applied to patches where the dot product is zero. Whisper thin layers are applied to patches whose normals are almost perpendicular to the view vector. In this case the dot product approaches one.
As paraphrased from the GNU General Public License "the following instances of program code are distributed in the hope that it will be useful, but without any warranty; without even the implied warranty of merchantability or fitness for a particular purpose." Please do not hesitate to notify me of any errors in logic and/or semantics. The implementation of the Mersenne Twister algorithm is released under the terms and conditions of the BSD License
NOTE: Assumptions have not been made on available hardware; thus, the following implementation is software-based only. Our goal is to convey ideas that appeal to the broadest of audiences. Binding any instance of sample code to the specific feature set of graphics hardware would imply a prefered solution where clearly many exist.
//////////////////////////////////////////////////////////// // // A C-program for MT19937, with initialisation improved // 2002/2/10. Coded by Takuji Nishimura and Makoto // Matsumoto. This is a faster version by taking Shawn // Cokus's optimisation, Matthe Bellew's simplification, // Isaku Wada's real version. // // Before using, initialise the state by using // init_genrand(seed) or init_by_array(init_key, key_length) // // Copyright (C) 1997 - 2002, Makoto Matsumoto and Takuji // Nishimura. All rights reserved. // // Redistribution and use in source and binary forms, with // or without modification, are permitted provided that the // following conditions are met: // // 1. Redistributions of source code must retain the above // copyright notice, this list of conditions and the // following disclaimer. // // 2. Redistributions in binary form must reproduce the // above copyright notice, this list of conditions and // the following disclaimer in the documentation and/or // other materials provided with the distribution. // // 3. The names of its contributors may not be used to // endorse or promote products derived from this software // without specific prior written permission. // // THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND // CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, // INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF // MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE // DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR // CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, // SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, // BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR // SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS // INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, // WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING // NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE // OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH // DAMAGE. // // Any feedback is very welcome. // http://www.math.keio.ac.jp/matumoto/emt.html // email: [email protected] // // Conversion into C++ class by Hin Jang (May 14, 2003) // https://hinjang.com/ // // ---------------------------------------------------------- // Mersenne.h // ---------------------------------------------------------- #ifndef __MERSENNE_H__ #define __MERSENNE_H__ // period parameters const unsigned long N = 624; const unsigned long M = 397; // constant vector a const unsigned long MATRIX_A = 0x9908b0dfUL; // most significant w-r bits const unsigned long UMASK = 0x80000000UL; // least significant r bits const unsigned long LMASK = 0x7fffffffUL; class Mersenne { public: Mersenne(unsigned long *, unsigned long); ~Mersenne(); unsigned long genrand_int32(void); long genrand_int31(void); double genrand_real1(void); double genrand_real2(void); double genrand_real3(void); double genrand_res53(void); private: unsigned long state[N]; // the array for the state vector int left; int initf; unsigned long *next; void init_by_array(unsigned long *, unsigned long); void init_genrand(unsigned long); void next_state(void); unsigned long mixBits(unsigned long, unsigned long); unsigned long twist(unsigned long, unsigned long); }; inline unsigned long Mersenne::mixBits(unsigned long u, unsigned long v) { return ( ((u) & UMASK) | ((v) & LMASK) ); } inline unsigned long Mersenne::twist(unsigned long u, unsigned long v) { return ( (mixBits(u, v) >> 1) ^ ((v) & 1UL ? MATRIX_A : 0UL) ); } #endif // __MERSENNE_H__ //////////////////////////////////////////////////////////// // // A C-program for MT19937, with initialisation improved // 2002/2/10. Coded by Takuji Nishimura and Makoto // Matsumoto. This is a faster version by taking Shawn // Cokus's optimisation, Matthe Bellew's simplification, // Isaku Wada's real version. // // Before using, initialise the state by using // init_genrand(seed) or init_by_array(init_key, key_length) // // Copyright (C) 1997 - 2002, Makoto Matsumoto and Takuji // Nishimura. All rights reserved. // // Redistribution and use in source and binary forms, with // or without modification, are permitted provided that the // following conditions are met: // // 1. Redistributions of source code must retain the above // copyright notice, this list of conditions and the // following disclaimer. // // 2. Redistributions in binary form must reproduce the // above copyright notice, this list of conditions and // the following disclaimer in the documentation and/or // other materials provided with the distribution. // // 3. The names of its contributors may not be used to // endorse or promote products derived from this software // without specific prior written permission. // // THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND // CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, // INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF // MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE // DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR // CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, // SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, // BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR // SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS // INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, // WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING // NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE // OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH // DAMAGE. // // Any feedback is very welcome. // http://www.math.keio.ac.jp/matumoto/emt.html // email: [email protected] // // Conversion into C++ class by Hin Jang (May 14, 2003) // https://hinjang.com/ // // ---------------------------------------------------------- // Mersenne.cpp // ---------------------------------------------------------- #include "mersenne.h" Mersenne::Mersenne(unsigned long *init_key, unsigned long key_length) { left = 1; initf = 0; init_by_array(init_key, key_length); } // default destructor // Mersenne::~Mersenne() { } // initializes state[N] with a seed // void Mersenne::init_genrand(unsigned long s) { int j; state[0]= s & 0xffffffffUL; for (j=1; j<N; j++) { state[j] = (1812433253UL * (state[j-1] ^ (state[j-1] >> 30)) + j); // See Knuth TAOCP Vol2. 3rd Ed. P.106 for multiplier. // In the previous versions, MSBs of the seed affect // only MSBs of the array state[]. // 2002/01/09 modified by Makoto Matsumoto // state[j] &= 0xffffffffUL; // for >32 bit machines } left = 1; initf = 1; } // initialise by an array with array-length // init_key is the array for initializing keys // key_length is its length // void Mersenne::init_by_array(unsigned long *init_key, unsigned long key_length) { int i, j, k; init_genrand(19650218UL); i = 1; j = 0; k = (N>key_length ? N : key_length); for (; k; k--) { // non linear state[i] = (state[i] ^ ((state[i-1] ^ (state[i-1] >> 30)) * 1664525UL)) + init_key[j] + j; state[i] &= 0xffffffffUL; // for WORDSIZE > 32 machines i++; j++; if (i >= N) { state[0] = state[N-1]; i = 1; } if (j>=key_length) { j = 0; } } for (k=N-1; k; k--) { // non-linear state[i] = (state[i] ^ ((state[i-1] ^ (state[i-1] >> 30)) * 1566083941UL)) - i; state[i] &= 0xffffffffUL; // for WORDSIZE > 32 machines i++; if (i >= N) { state[0] = state[N-1]; i=1; } } state[0] = 0x80000000UL; // MSB is 1; // assuring non-zero initial array left = 1; initf = 1; } void Mersenne::next_state() { unsigned long *p=state; int j; // if init_genrand() has not been called, // a default initial seed is used // if (initf == 0) init_genrand(5489UL); left = N; next = state; for (j=N-M+1; --j; p++) { *p = p[M] ^ twist(p[0], p[1]); } for (j=M; --j; p++) { *p = p[M-N] ^ twist(p[0], p[1]); } *p = p[M-N] ^ twist(p[0], state[0]); } // generates a random number on [0,0xffffffff]-interval // unsigned long Mersenne::genrand_int32() { unsigned long y; if (--left == 0) next_state(); y = *next++; // Tempering // y ^= (y >> 11); y ^= (y << 7) & 0x9d2c5680UL; y ^= (y << 15) & 0xefc60000UL; y ^= (y >> 18); return y; } // generates a random number on [0,0x7fffffff]-interval // long Mersenne::genrand_int31() { unsigned long y; if (--left == 0) next_state(); y = *next++; // Tempering // y ^= (y >> 11); y ^= (y << 7) & 0x9d2c5680UL; y ^= (y << 15) & 0xefc60000UL; y ^= (y >> 18); return (long)(y>>1); } // generates a random number on [0,1]-real-interval // double Mersenne::genrand_real1() { unsigned long y; if (--left == 0) next_state(); y = *next++; // Tempering // y ^= (y >> 11); y ^= (y << 7) & 0x9d2c5680UL; y ^= (y << 15) & 0xefc60000UL; y ^= (y >> 18); return (double)y * (1.0/4294967295.0); // divided by 2^32-1 } // generates a random number on [0,1)-real-interval // double Mersenne::genrand_real2() { unsigned long y; if (--left == 0) next_state(); y = *next++; // Tempering // y ^= (y >> 11); y ^= (y << 7) & 0x9d2c5680UL; y ^= (y << 15) & 0xefc60000UL; y ^= (y >> 18); return (double)y * (1.0/4294967296.0); // divided by 2^32 } // generates a random number on (0,1)-real-interval // double Mersenne::genrand_real3() { unsigned long y; if (--left == 0) next_state(); y = *next++; // Tempering // y ^= (y >> 11); y ^= (y << 7) & 0x9d2c5680UL; y ^= (y << 15) & 0xefc60000UL; y ^= (y >> 18); return ((double)y + 0.5) * (1.0/4294967296.0); // divided by 2^32 } // generates a random number on [0,1) with 53-bit resolution // double Mersenne::genrand_res53() { unsigned long a = genrand_int32()>>5; unsigned long b = genrand_int32()>>6; return(a*67108864.0+b)*(1.0/9007199254740992.0); } // These real versions are due to Isaku Wada, 2002/01/09 // added // ---------------------------------------------------------- // perlin.h // ---------------------------------------------------------- // Code derived from the Java reference implementation by // K. Perlin 2002 ( http://mrl.nyu.edu/~perlin/noise/ ) // #ifndef __PERLIN_H__ #define __PERLIN_H__ #include "mersenne.h" // pseudo-random number generator #include <math.h> // floor() function class Perlin { public: Perlin(); ~Perlin(); double noise(double, double, double); double bias(double, double); double gain(double, double); private: double fade(double); double grad(int, double, double, double); double lerp(double, double, double); int *p; int *permutation; }; inline double Perlin::fade(double t) { return t * t * t * (t * (t * 6.0 - 15.0) + 10.0); } inline double Perlin::grad(int hash, double x, double y, double z) { // covert lower four bits of hash code into twelve // gradient directions int h = hash & 15; double u = ( h<8||h==12||h==13 ) ? x : y; double v = ( h<4||h==12||h==13 ) ? y : z; return ((h&1) == 0 ? u : -u) + ((h&2) == 0 ? v : -v); } inline double Perlin::lerp(double t, double a, double b) { return a + t * (b - a); } inline double Perlin::bias(double t, double a) { return (t) / ((1.0/(a) - 2.0) * (1.0 - (t)) + 1.0); } inline double Perlin::gain(double t, double a) { return ((t) < 0.5) ? ( (t) / ((1.0/(a) - 2.0) * (1.0 - 2.0*(t)) + 1.0) ) : ( ((1.0/(a) - 2.0) * (1.0 - 2.0*(t)) - (t)) / ((1.0/(a) - 2.0) * (1.0 - 2.0*(t)) - 1.0) ); } #endif // __PERLIN_H__ // ---------------------------------------------------------- // perlin.cpp // ---------------------------------------------------------- #include "perlin.h" Perlin::Perlin() { int i; p = new int[512]; permutation = new int[256]; // seed values for Mersenne Twister algorithm // unsigned long init[4] = {0x123, 0x234, 0x345, 0x456}; unsigned long length = 4; // initialise pseudo-random number generator // Mersenne *rnGenerator = new Mersenne(init, length); // build permutation table // for (i=0; i<256; ++i) { permutation[i] = rnGenerator->genrand_int32() >> 24; p[i+256] = p[i] = permutation[i]; } delete rnGenerator; } // default destructor // Perlin::~Perlin() { delete [] p; delete [] permutation; } double Perlin::noise(double x, double y, double z) { // Code derived from the Java reference implementation by // K. Perlin 2002 ( http://mrl.nyu.edu/~perlin/noise/ ) // double shade; // find unit cube that contains the point // int X = (int)floor(x) & 255; int Y = (int)floor(y) & 255; int Z = (int)floor(z) & 255; // find the relative coordinate of the point in the cube // x -= floor(x); y -= floor(y); z -= floor(z); // compute the fade curves for each coordinate // double u = fade(x); double v = fade(y); double w = fade(z); // compute the hash coordinate the eight corners of the cube int A = p[X] + Y; int AA = p[A] + Z; int AB = p[A+1] + Z; int B = p[X+1] + Y; int BA = p[B] + Z; int BB = p[B+1] + Z; // add the blended results from the eight corners of the cube // shade = lerp(w, lerp(v, lerp(u, grad(p[AA ], x, y, z), grad(p[BA ], x-1, y, z)), lerp(u, grad(p[AB ], x, y-1, z), grad(p[BB ], x-1, y-1, z))), lerp(v, lerp(u, grad(p[AA+1], x, y, z-1), grad(p[BA+1], x-1, y, z-1)), lerp(u, grad(p[AB+1], x, y-1, z-1), grad(p[BB+1], x-1, y-1, z-1)))); return shade; }
[87] Cabral, B., and Leith (Casey) Leedom, Imaging Vector Fields Using Line
Integral Convolution, Computer-Generated Watercolor, ACM Computer Graphics,
SIGGRAPH 1993 Proceedings, 27(4):263-272
[88] Curtis, Cassidy J., Sean E. Anderson, Joshua E. Seims, Kurt W. Fleischer
and David H. Salesin, Computer-Generated Watercolor, ACM Computer Graphics,
SIGGRAPH 1997 Proceedings, 31(4):421-430
[89] Gooch, Amy Ashurst and Bruce Gooch, Nonphotorealistic Rendering, A.K.
Peters Ltd., ISBN: 1568811330, July 2001
[90] Haase, Chet S., and Gary W. Meyer, Modeling Pigmented Materials for
Realistic Image Synthesis, ACM Transactions on Graphics, 11(4):305-335,
October 1992
[91] Hertzmann, Aaron, Fast Paint Texture, ACM Symposium on Nonphotorealistic
Animation and Rendering (NPAR) 2002, 91 - ff
[92] Hertzmann, Aaron, and Denis Zorin, Illustrating Smooth Surfaces, ACM
Computer Graphics, SIGGRAPH 2000 Proceedings, 34(3):517 - 526
[93] Lake, Adam, Carl Marshall, Mark Harris, Marc Blackstein, International
Symposium on Nonphotorealistic Animation and Rendering (NPAR) 2000, 13-20
[94] Lum, Eric B., and Kwan-Liu Ma, Nonphotorealistic Rendering Using
Watercolor Inspired Textures and Illumination, Department of Computer
Science, University of California, Davis, 2001
[95] Markosian, Lee, Lichael A. Kowalski, Samuel J. Trychin, Lubomir D.
Bourdev, Daniel Goldstein, and John F. Hughes, Real-Time Nonphotorealistic
Rendering, Brown University, NSF Science and Technology Centre, Computer
Graphics and Scientific Visualisation, 1997
[96] Perlin, Ken, An Image Synthesiser, ACM Computer Graphics, SIGGRAPH 1985
Proceedings, 19(4):287 - 296
[97] Perlin, Ken, Improving Noise, ACM Computer Graphics, SIGGRAPH 2002
Proceedings, 36(3):681 - 682
[98] Stalling, Detlev and Hans-Christian Hege, Fast and Resolution
Independent Line Integral Convolution, Computer-Generated Watercolor, ACM
Computer Graphics, SIGGRAPH 1995 Proceedings, 29(4):249-256
Powerful computer hardware and clever algorithms are two reasons for the growing popularity of subdivision schemes in the efficient generation of freeform surfaces. Such methods are simple, robust and have many practical applications. A relatively new scheme for triangle meshes is called "square root three" subdivision. This rather peculiar name is derived from the fact that if we apply the same subdivision step twice the combined result is the tri-section of each original edge in the mesh [100]. In other words, the scheme creates three edges per two refinement steps for each triangle.
Almost three decades ago, Chaikin introduced an ingenious method for generating curves [68]. The algorithm was a corner cutting or refinement scheme that produced a smooth curve from a given control polygon. In the following years, many subdivision schemes for modeling smooth surfaces have been developed based on Chaikin's pioneering endeavour.
An algorithm that subdivides a surface applies some basic rules to vertices, edges and faces. The rule to generate a new vertex is called a vertex mask or stencil. Likewise, the rules to generate new edges and new faces are called, respectively, edge masks and face masks. Chaikin's scheme of corner cutting applies a vertex mask to each pair of vertices to establish two new vertices.
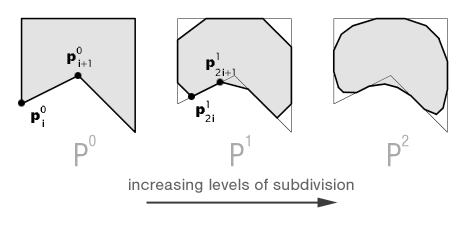
The leftmost shape is known as the initial control mesh P0 where the superscript denotes its level of subdivision. As we subdivide, the shape becomes more refined. Continuing this process to some predefined limit yields a shape called the limit surface. With Chaikin's scheme the next control mesh has double the number of vertices as the mesh before it. The vertex mask, in this case, is simply
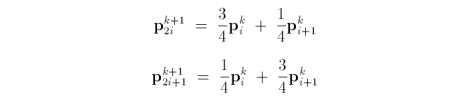
where k is the subdivision level for the i-th vertex p in control mesh P k. Each new vertex is the weighted sum of two vertices in the previous subdivision level. Chaikin's scheme is an approximating subdivision technique because a given mesh does not retain vertices from the previous subdivision step. The scheme is stationary because it uses the same masks at every subdivision step, and the scheme is also uniform because it uses the same masks for every vertex.
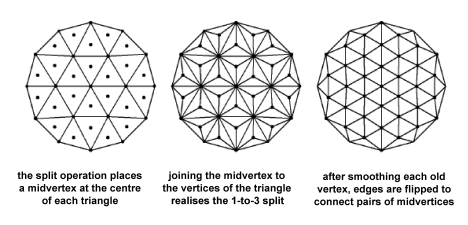
The refinement of the base mesh begins with a split operation. A new vertex, called the midvertex, is placed at the center of each triangle. This 1-to-3 split introduces three new edges connecting the new vertex to each vertex of the original triangle. The mask is
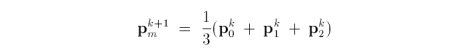
Next, we perform a smoothing operation of each old vertex. For simplicity, we assume the mask is a 1-ring neighbourhood containing the vertex and its direct neighbours.
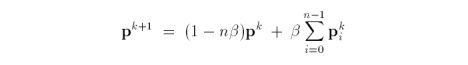
where Β is a function of valence n. Kobbelt derived an ideal choice for Β(n) to ensure second-degree parametric continuity at most vertices.
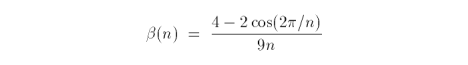
Along the boundaries of an open mesh, the subdivision rules only use the boundary vertices and never the interior vertices. The masks in this case are
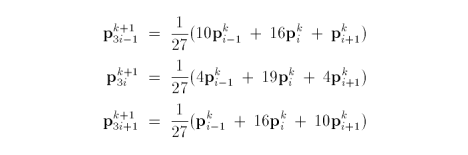
Finally, the old edges are flipped to connect pairs of midvertices. The stages of a single subdivision step can be visualised as follows (image courtesy of Leif Kobbelt [100] and used by permission).
Freeform surfaces that are generated via subdivision schemes have the potential of amassing tremendous polygon counts. Efficient data structures must be used to ensure optimal run-time performance and minimal memory consumption. OpenMesh is one such data structure that not only meets this criteria but can also be used to represent and manipulate any polygonal mesh. Complete details are available from OpenMesh.org.
As paraphrased from the GNU General Public License "the following instances of program code are distributed in the hope that it will be useful, but without any warranty; without even the implied warranty of merchantability or fitness for a particular purpose." Please do not hesitate to notify me of any errors in logic and/or semantics.
// ----------------------------------------------------------
// sqrt3.h (Partial implementation only)
// ----------------------------------------------------------
#ifndef __SQRT3_H__
#define __SQRT3_H__
#include <vector>
#include <math.h>
using namespace std;
typedef struct {
double x, y, z; // Cartesian coordinates
double nx, ny, nz; // normal
} Vertex;
typedef struct {
Vertex p[3];
} Triangle;
class Sqrt3
{
public:
Sqrt3();
~Sqrt3();
private:
Vertex split(Triangle *);
Vertex smooth(Vertex *, vector<Vertex>);
};
#endif // __SQRT3_H__
// ----------------------------------------------------------
// sqrt3.cpp (Partial implementation only)
// ----------------------------------------------------------
#include "sqrt3.h"
Sqrt3::Sqrt3() { }
Sqrt3::~Sqrt3() { }
Vertex Sqrt3::split(Triangle *t)
{
int i;
Vertex v;
v.x = v.y = v.z = 0.0;
v.nx = v.ny = v.nz = 0.0;
for (i=0; i<3; ++i) { // compilers should
// unroll this loop
v.x += t->p[i].x;
v.y += t->p[i].y;
v.z += t->p[i].z;
v.nx += t->p[i].nx;
v.ny += t->p[i].ny;
v.nz += t->p[i].nz;
}
v.x /= 3.0;
v.y /= 3.0;
v.z /= 3.0;
v.nx /= 3.0;
v.ny /= 3.0;
v.nz /= 3.0;
return v;
}
Vertex Sqrt3::smooth(Vertex *v, vector<Vertex> neighbour)
{
vector<Vertex>::iterator iter;
Vertex nv, p;
double beta;
double sum[6];
int n;
n = neighbour.size();
beta = (4 - 2*cos(2*M_PI/n)) / (9*n);
nv.x = (1 - n*beta)*v->x;
nv.y = (1 - n*beta)*v->y;
nv.z = (1 - n*beta)*v->z;
nv.nx = (1 - n*beta)*v->nx;
nv.ny = (1 - n*beta)*v->ny;
nv.nz = (1 - n*beta)*v->nz;
// initialise sum[]
//
iter = neighbour.begin();
p = *iter;
sum[0] = p.x;
sum[1] = p.y;
sum[2] = p.z;
sum[3] = p.nx;
sum[4] = p.ny;
sum[5] = p.nz;
// iterate through remaining neighbours
//
++iter;
while (iter != neighbour.end()) {
p = *iter;
sum[0] += p.x;
sum[1] += p.y;
sum[2] += p.z;
sum[3] += p.nx;
sum[4] += p.ny;
sum[5] += p.nz;
++iter;
}
// complete smoothing of 'nv'
//
nv.x += beta*sum[0];
nv.y += beta*sum[1];
nv.z += beta*sum[2];
nv.nx += beta*sum[3];
nv.ny += beta*sum[4];
nv.nz += beta*sum[5];
return nv;
}
[68] Chaikin, George M., An algorithm for high speed curve generation, Computer
Vision, Graphics and Image Processing, 3(4):346 - 349, 1974
[99] Botsch, M., S. Steinberg, S. Bischoff and L. Kobbelt, OpenMesh — a
generic and efficient polygon mesh data structure, OpenSG Symposium 2002
[100] Kobbelt, Leif, Sqrt(3) Subdivision, ACM Computer Graphics, SIGGRAPH 2000
Proceedings, 34(3):103 - 112
[101] Oswald, Peter and Peter Schröder, Composite Primal/Dual Sqrt(3)
Subdivision Schemes, Caltech Multi-Res Modeling Group, Computer Science
Department, 2002